I am currently a Senior Software Engineer at Google DeepMind, working on Image Generation from Gemini. I was a post-training co-lead and pre-training core-contributor for nano banana pro. Before this, I was a core contributor to the first native image generation launch in Gemini.
I also contributed to the launch of Gemini 1.5 and Gemini 2.5 through my work on MultiModal Post-training. Prior to Google, I was at Waymo on the Perception Team, where I enhanced data efficiency for perception models.
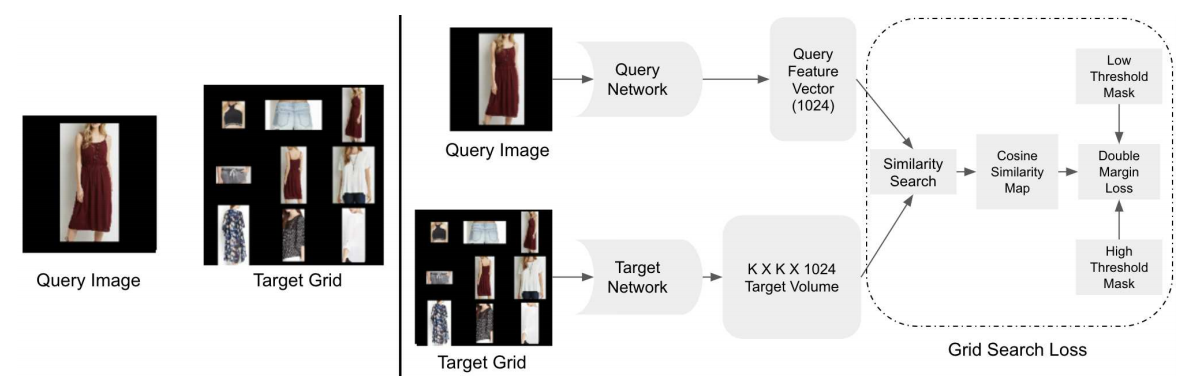
I graduated with a Master's degree in Computer Science from Stanford University in 2021. During my Master's, I was a Research Assistant under Professor Stefano Ermon, researching generative models and self-supervised learning. One of my projects won the Best Paper Award at ICLR, 2022. Prior to my Masters, I worked at Adobe India on a deep learning-based visual search product for clothing recommendation. This work won the Best Paper Award at a CVPR workshop, 2019.
I am interested in Large Vision Language Models, Generative Models, Post-training RL algorithms, self-supervised learning, and active learning.
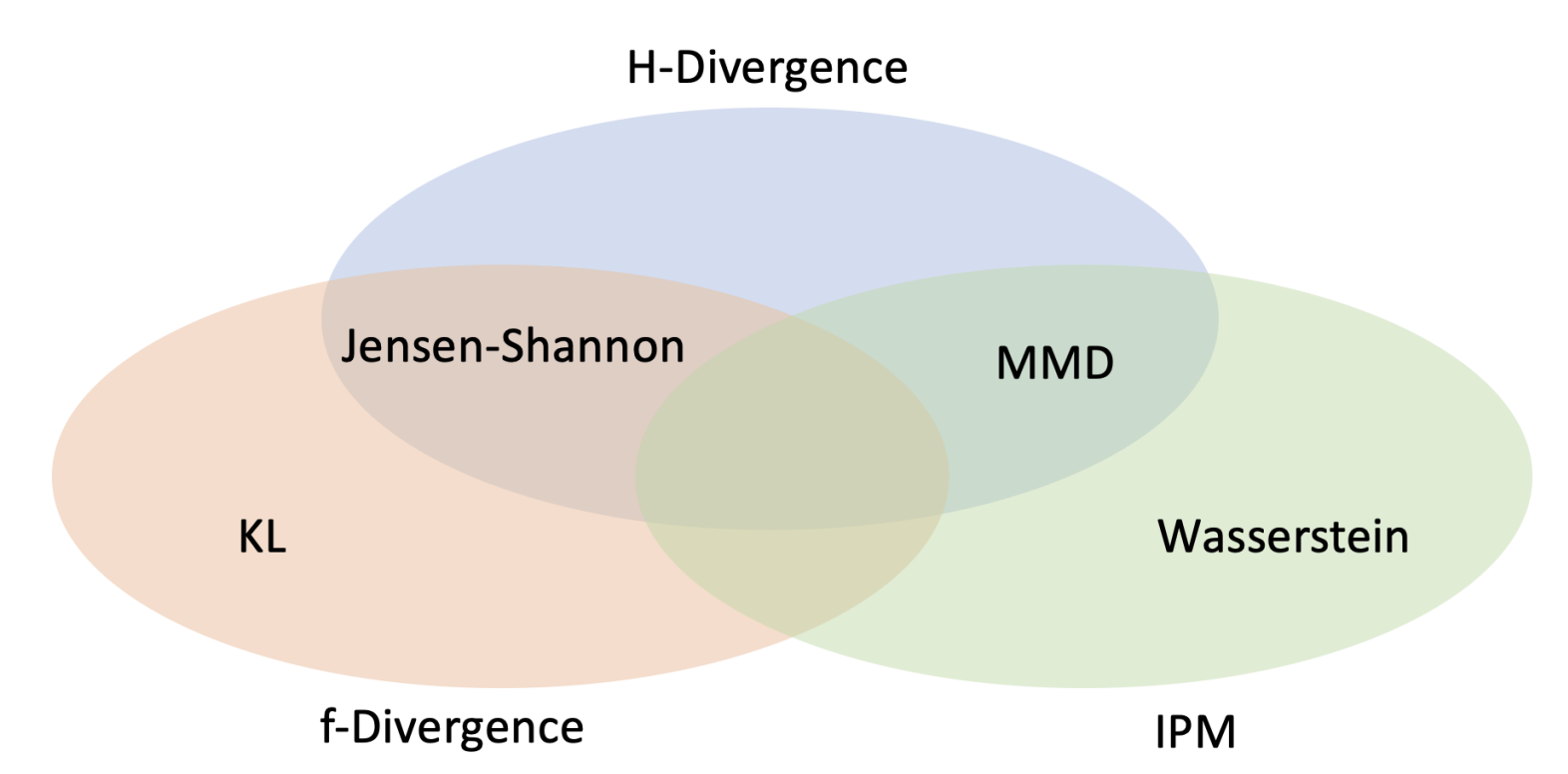
Proposed a way to measure the discrepancy between two probability distributions based on optimal decision loss. Our approach outperformed prior approaches for two-sample tests across different datasets. The proposed divergence can also be used for feature selection, sample quality evaluation or even studying the effect of climate change.
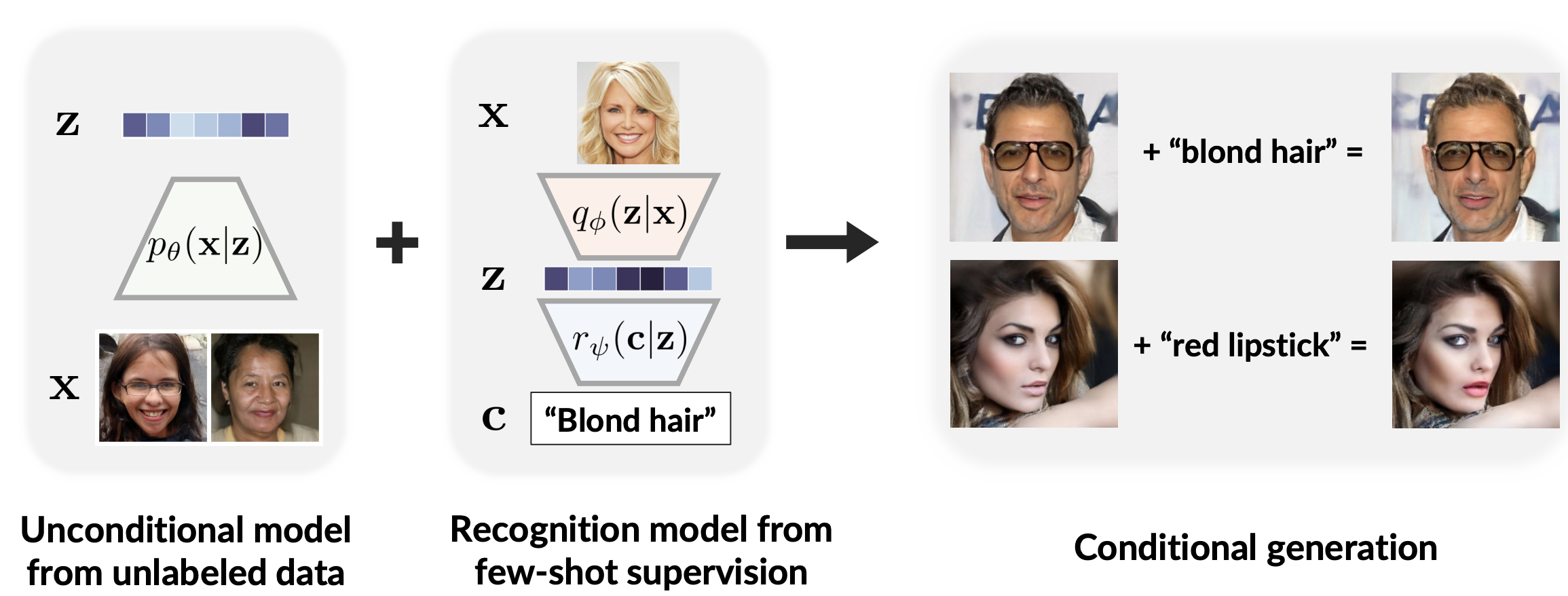
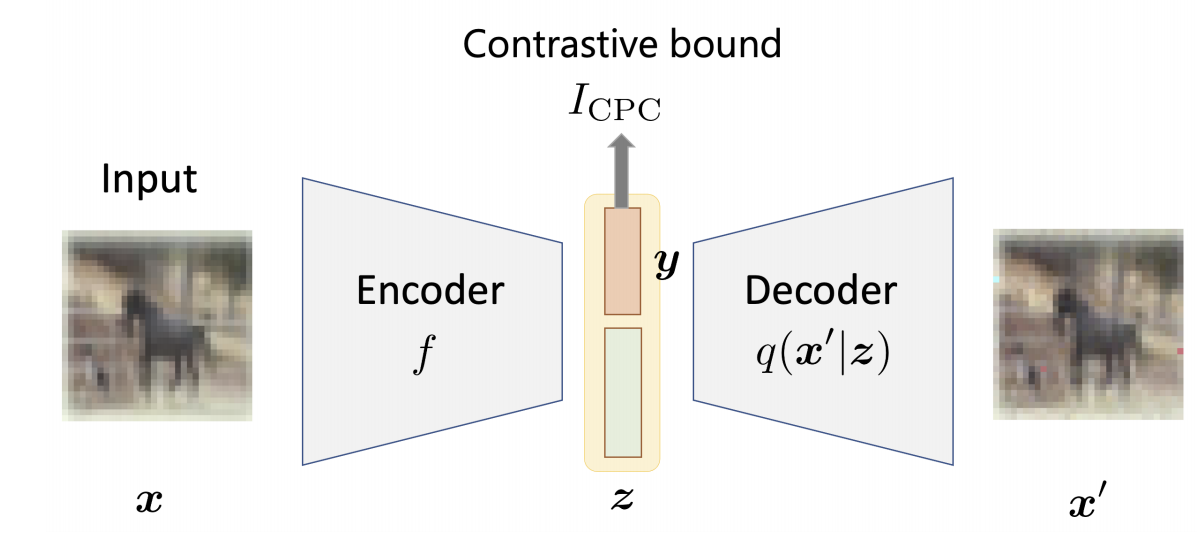
Developed a single model that can both learn rich latent representations, and sample images from that latent space. Added contrastive loss on top of VAE to learn good representations and learnt a strong prior over the latent space of VAE, using diffusion models. Our model allows us to perform few shot conditional generation tasks, such as conditional image manipulation with limited examples.
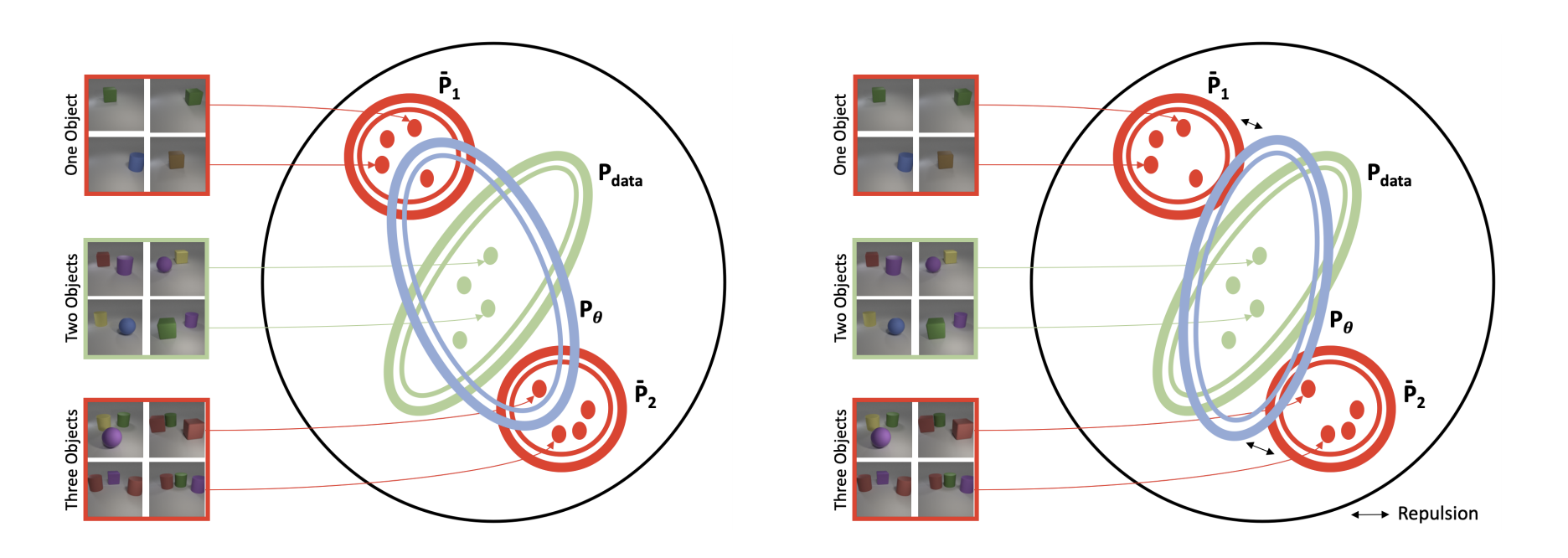
Proposed a new GAN training objective to incorporate negative data augmentation. Obtained significant gain in conditional/unconditional image generation and anomaly detection using the discriminator. Incorporated negative augmentations for contrastive learning based approaches for images and videos and achieved gains in linear classification.
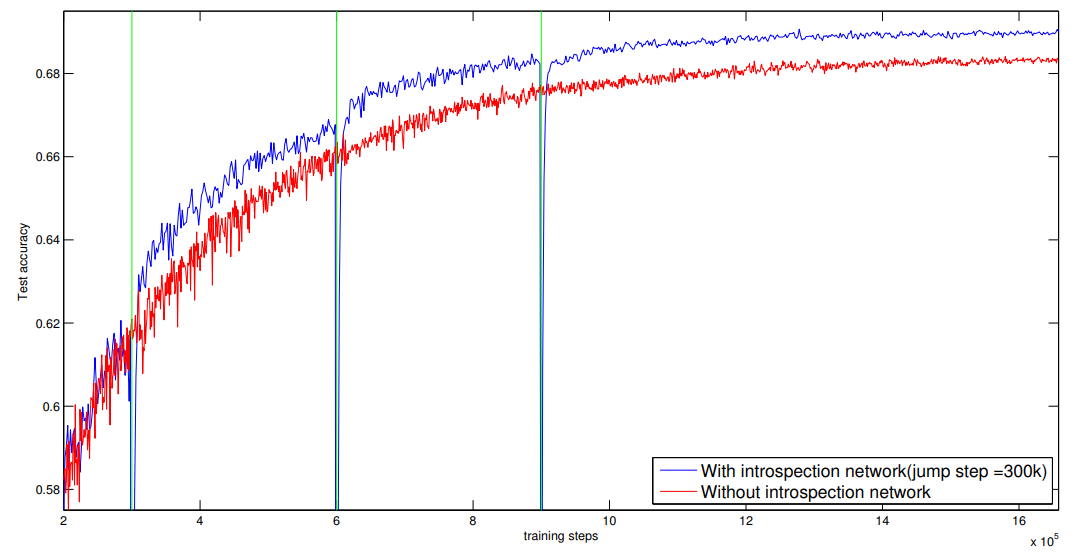
Developed an algorithm to speed up training of deep neural networks by predicting future weight values. Achieved 20% and 40% improvement in training time for Cifar-10 and ImageNet datasets respectively.
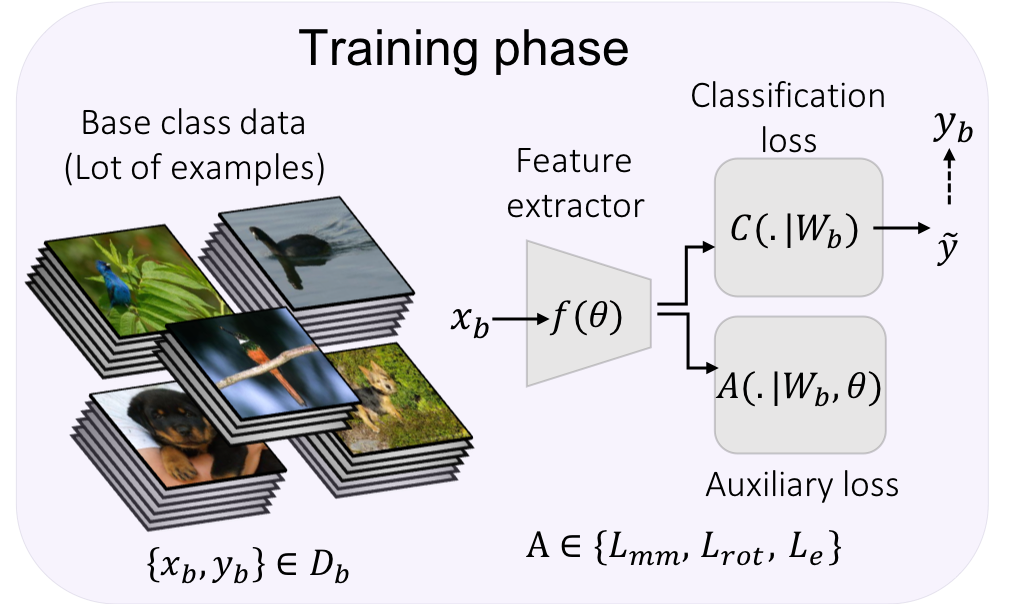
Used self-supervision techniques - rotation and exemplar, followed by manifold mixup for few-shot classification tasks. The proposed approach beats the current state-of-the-art accuracy on mini-ImageNet, CUB and CIFAR-FS datasets by 3-8%.
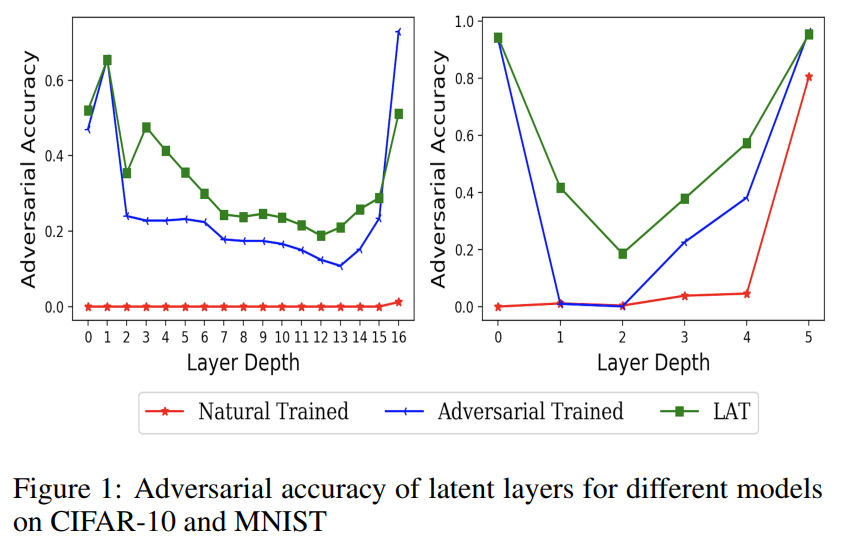
Analyzed the adversarial trained models for vulnerability against adversarial perturbations at the latent layers. The algorithm achieved the state-of-the art adversarial accuracy against strong adversarial attacks.
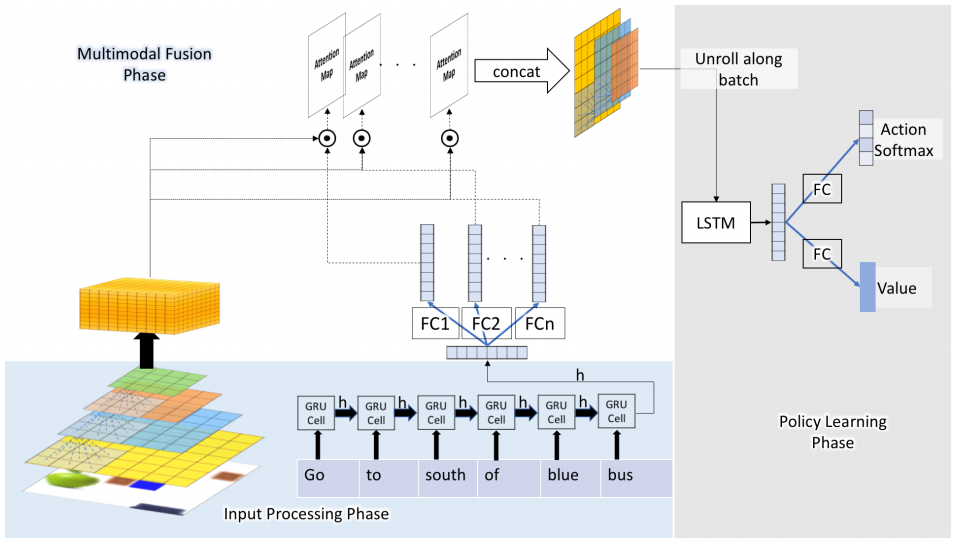
Made a 2D grid environment in which an agent performs tasks on the basis of natural language sentence. Developed a new fusion mechanism for the fusion of visual and textual features to solve the problem. The proposed methodology outperformed the state-of-the-art in terms of both speed and performance for the 2D as well as a 3D environment.
Proposed a hybrid model that can be used both as a generative as well as a representation learning model. Trained auto-encoder with contrastive learning to learn good representations, followed by diffusion model over the latent space to learn a generative model.
Paper accepted at ICLR 2021 Workshop: Neural Compression: From Information Theory to Applications.
Analyzed the models adversarially trained with small perturbation. Such models have interpretable gradients without incurring a significant drop in the performance over clean images. Used these models for zero-shot transfer and weakly supervised object localization tasks, achieving significant gains in performance.
Paper accepted at ICLR 2020 Workshop: Towards Trustworthy ML.
Proposed a multi-conditional image generation pipeline that generates an image which contains the shape of first input and texture of second input image.
Paper accepted at NeurIPS Workshop on Machine Learning for Creativity and Design 3.0, 2019.
Implemented Deep Q learning for a maze pathfinder. Built the game in pygame which could be then controlled by a deep learning agent to find the optimal path.